Unsupervised Learning of Visual Representations using Videos
|
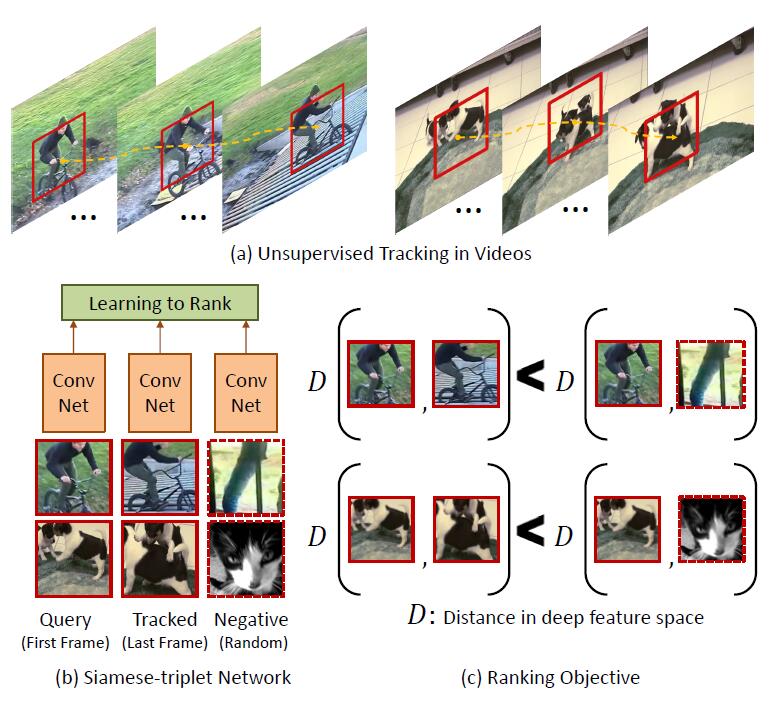
| Is strong supervision necessary for learning a good visual representation? Do we really need millions of semantically-labeled images to train a Convolutional Neural Network (CNN)? In this paper, we present a simple yet surprisingly powerful approach for unsupervised learning of CNN. Specifically, we use hundreds of thousands of unlabeled videos from the web to learn visual representations. Our key idea is that visual tracking provides the supervision. That is, two patches connected by a track should have similar visual representation in deep feature space since they probably belong to the same object or object part. We design a Siamese-triplet network with a ranking loss function to train this CNN representation. Without using a single image from ImageNet, just using 100K unlabeled videos and the VOC 2012 dataset, we train an ensemble of unsupervised networks that achieves 52% mAP (no bounding box regression). This performance comes tantalizingly close to its ImageNet-supervised counterpart, an ensemble which achieves a mAP of 54.4%. We also show that our unsupervised network can perform competitively in other tasks such as surface-normal estimation. |
People
Paper

|
Xiaolong Wang and Abhinav Gupta Unsupervised Learning of Visual Representations using Videos Proc. of IEEE International Conference on Computer Vision (ICCV), 2015 [PDF] [code] [models] [mined_patches] |
Tracking Video Samples
Acknowledgements
This work was partially supported by ONR MURI N000141010934 and NSF IIS 1320083. This material was also based on research partially sponsored by DARPA under agreement number FA8750-14-2-0244. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of DARPA or the U.S. Government. The authors would like to thank Yahoo! and Nvidia for the compute cluster and GPU donations respectively.